1. replace와 translate
1) replace : 단어 치환 삭제
** 사용법 : replace(대상,찾을단어[,바꿀단어])
2) translate : 글자 치환 삭제
** 사용법 : translate(대상,찾을문자열,바꿀문자열)
- 찾을문자열과 바꿀문자열 글자별로 매핑하여 치환
- 찾을문자열 길이 < 바꿀문자열 길이 : 바꿀문자열의 나머지 글자 무시
- 찾을문자열 길이 > 바꿀문자열 길이 : 바꿀문자열에 빈문자열 전달 시 모든 글자 삭제됨
- 바꿀문자열 생략 불가
예제1)
select replace('abcba','ab','AB'), --ABcba
translate('abcba','ab','AB') --ABcBA
from dual;
select translate('abcba','ab','ABC'), --ABcBA ----> 일대일로 대응되는데 C는 대응될게 없으면 무시함.
translate('abcba','abc','AB') --ABBA ----> c는 빈문자열이 짝이 되었기 때문에 삭제됨.
예제2) student 테이블에서 각 학생의 이름, 전화번호를 출력
단, 전화번호는 다음과 같은 형태로 출력
055)381-2158 => 0553812158
select tel,
translate(tel, '1)-', '1') newtel
from student;
바꿀문자열에 빈문자열 전달 시 tel의 전체가 삭제되므로 자리를 채우기 위한 임의글자(1) 전달
단, 임의글자로 다른 문자가 치환되면 안되므로 1을 찾을문자열에도 전달해야 함
예제3) professor 테이블의 id 컬럼의 모든 숫자 삭제
select id, translate(id,'a0123456789','a') "삭제된 id"
from professor;
즉, translate는 가운데와 마지막이 수학으로 생각하면 1:1 대응이라고 생각하면 이해하기 편함.
[ 연습문제 ]
1. professor 테이블에서 101번 학과 소속 교수의 이름, 직급, 학과번호(deptno) 출력
단, 직급은 교수 또는 강사로만 출력되도록 함.
sol)
select name 이름,
translate(position,'1정조전임','1') as 직급,
deptno 학과번호
from professor
where deptno = 101;
결과는

1은 1로 대응 되지만 나머지 정조전임은 대응될게 없으므로 사라진다.
2. dept2 테이블에서 area 값을 아래와 같이 변경
본사 -> 본수, 지사ㅣ=> 본사
sol)
select * from dept2;
select dcode 코드,
dname 사무실이름,
pdept 번호,
replace(replace(area,'본사','본부'),'지사','본사') as 위치
from dept2;
결과는

다음처럼 replace함수를 두번 씌워서 사용하는 방법도 많이 이용된다.
2. 문자열 삽입 : lpad, rpad
- 문자열을 정해진 길이만큼 채우는 함수
** 사용법 : lpad(대상,총자리수,채울문자)
- 채울문자 생략 시 공백 삽입
- 총크기는 bytes를 의미
- 원본문자열의 크기보다 더 작은 숫자를 총크기로 전달 시 원본문자열 손상(일부 잘림)
다음을 살펴보자.
select lpad('abcd',10,'*'), rpad('abcd',10,'*'),
lpad('abcd',10), length(rpad('abcd',10))
from dual;

다음 결과를 얻을 수 있는데 LPAD 는 왼쪽으로 문자열을 삽입하는 것이기 때문에 원래 문자는 오른쪽으로 보내진다.
RPAD는 오른족으로 문자열을 삽입하는 것이기 때문에 원래 문자는 왼쪽으로 보내지게 된다.
select lpad('abcd',2,'*')
from dual;

또한 다음 결과와 같이 총길이를 원본문자열 길이보다 더 작게 전달하면 원본문자열이 일부 잘려서 출력된다.
3. 문자열 또는 공백 삭제 : trim, ltrim, rtrim
-- - ltrim, rtrim은 각각 왼쪽, 오른쪽에서부터 원하는 문자열 또는 공백 제거
-- - trim은 양쪽에 있는 공백만 제거 가능
--** 사용법
--1) ltrim(대상[,제거문자열])
-- - 제거문자열 생략 시 공백 제거
--2) trim (대상) : only 공백제거용으로만 사용한다.
select ltrim('aabacaaa', 'a'),
rtrim('aabacaa','a'),
ltrim(' bac '),
rtrim(' bac ')
from dual;
결과는

LTRIM은 왼쪽에 있는 'A'를 쭉 삭제하다가 다른문자가 나오면 실행을 멈춘다.
RTRIM또한 오른쪽부터 위와 마찬가지의 결과를 얻을 수 있다.
select trim('aabacaaa','a')
from dual; --에러발생(두번째 인수 전달 불가)
활용예1) 불필요한 공백이 삽입된 문자열 비교 시 사용
id
'abcd '
id = 'abcd'; -- 조회불가
trim(id) = 'abcd'; -- 조회가능
활용예2) 불필요한 공백이 삽입된 문자열의 그룹연산
지역 상호명 매출 지역별 매출 총합
서울 a 10 지역 매출
서울 b 20 => 서울 10
경기 c 15 서울 20 => 서울 지역에 불필요한 공백 삽입으로 인해 하나의 그룹으로 묶이지 않는 현상
경기 d 25 경기 40
[ 공백으로 인한 조회 및 그룹명 문제 테스트 ]
create table test1(
지역1 char(5), //고정형 ex) abc를 쓰면 공백이 2개 생김 // 주로 주민번호 같이 고정된 숫자 사이즈에서 사용
지역2 varchar2(5), //가변형 : 사이즈가 다른 경우에 사용한다. 공백을 허용하지 않는다.
상호명 varchar2(10),
매출 number);
insert into test1 values('서울','서울','A',100);
insert into test1 values(' 서울',' 서울','B',200);
insert into test1 values('서울 ','서울 ','C',300);
insert into test1 values('경기','경기','D',150);
insert into test1 values('경기','경기','E',250);
commit;
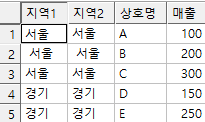
다음과 같은 테이블이 만들어 졌다.
비교예시1)
char 타입인 경우 문자열 비교시 뒷 공백 제거 후 비교(앞공백 무시 X)
select *
from test1
where 지역1 = '서울';

다음과 같이 서울지역이 상호가 A,C인 행이 출력된다. 상호가 B인 행은 출력이 되지 않았다.
varchar 타입인 경우 문자열 비교시 뒷 공백 제거하지 않고 비교(앞뒤공백 모두 무시하지 않고 그대로 비교)
select *
from test1
where 지역2 = '서울';

다음 결과를 볼 수 있듯이 상호가 A인 행이 출력되었는데, 이는 뒷 공백까지 무시하지 않고 출력된 결과이다.
select *
from test1
where trim(지역2) = '서울'; --> 모두 나옴

그러므로 trim을 이용해서 앞 뒤 공백을 모두 제거한채로 출력하면 문제없이 가능하다.
비교예시 2)
select 지역1, sum(매출)
from test1
group by 지역1;

: 서울이 두개 그룹으로 나뉨(서울 앞의 앞공백 때문에 서로 다른 서울로 인지)
select 지역2, sum(매출)
from test1
group by 지역2;

: 서울이 세 그룹으로 나뉨(앞,뒤 공백을 모두 무시하지 않았기 때문)
'SQL' 카테고리의 다른 글
| 8. 일반함수(2), 숫자함수 (0) | 2024.10.18 |
|---|---|
| 7. 일반함수(1) (1) | 2024.10.16 |
| 5. 문자열 함수(1) (1) | 2024.10.15 |
| 4. 연결연산자(||), 논리연산자 (5) | 2024.10.15 |
| 3. Order by 절, 중복행 제거 (0) | 2024.10.15 |



