[ 윈도우 함수 ]
- 테이블 추가 접근(조인, 서브쿼리)없이 다른행과의 비교, 연산을 가능하게 하는 문법
- select절에서만 사용 가능(where절 사용 불가)
** 종류
1. 집계함수 형태
sum(*), min, max, count, avg ... over(...)
ex) 누적합, 누적count
2. 순위(*)
- rank over()
- dense_rank over()
- row_number over()
ex) 성적이 높은순 순위
3. 이전/이후
- lag over()
- lead over()
ex) 이전 연도에 비해 매출 감소한 연도 확인
4. 최대/최소
- first_value over()
- last_value over()
5. 비율
- ratio_to_report over()
- cume_dist over()
- percent_rank over()
;
[ 집계함수 형태 윈도우함수 ]
1. sum over() : 누적합 연산
** 문법
sum(대상) over([partition by ...]
[order by ...]
[range|rows between A and B])
** 범위 전달
range : 값이 같은 경우 하나의 그룹으로 묶어 동시 연산(default)
row : 각 행씩 연산
A) unbounded preceding : 처음부터(default)
n preceding : n 이전부터
current row : 현재행부터
B) current row : 현재행까지(default)
unbounded following : 끝까지
n following : n 이후까지
** 특징
- 그룹별 연산 수행 시 partition by 사용(group by와 같은 기능)
- 누적합 연산 시 order by 필수
- 연산 범위 생략 시 range between unbounded preceding and current row
예제) 각 직원의 사번, 이름, 급여, 부서번호와 함께 각 부서의 급여 총합 함께 출력
sol1)
select empno, ename, sal, deptno,
(select sum(sal) from emp where deptno = e1.deptno) as sumsal
from emp e1
order by deptno;

또는
select e.empno, e.ename, e.sal, e.deptno, i.sumsal
from emp e, (select deptno, sum(sal) as sumsal
from emp
group by deptno) i
where e.deptno = i.deptno
order by deptno;
둘다 결과는 같음을 알 수 있다. 하지만 서브쿼리 혹은 조인을 이용하게 되면
코스트가 높아지기 때문에 쿼리 성능면에서 떨어짐을 알 수 있으므로 다음 해결법이 더 좋다.
sol2)
select empno, ename, sal, deptno,
sum(sal) over() as 전체급여총합,
sum(sal) over(partition by deptno) as 부서별급여총합
from emp e1
order by deptno;
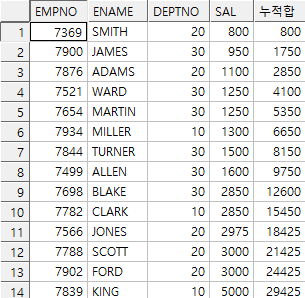
예제) 급여순서대로 급여 누적 합
select empno, ename, deptno, sal,
sum(sal) over(order by sal) as 누적합
from emp;

현대 답을 살펴보면 4번과 5번의 누적합이 같게 나옴을 알 수 있다.
(** 주의 : sal 순서대로 값이 같은 경우 누적합을 sal 값이 같은 값을 하나로 묶어서 동시에 연산 처리)
그러므로 4번과 5번은 동시에 묶어서 처리됨을 알 수 있다. 그럼 이 문제에 대한 해결법 2가지를 살펴보자.
해결1) 추가 정렬값 전달
select empno, ename, deptno, sal,
sum(sal) over(order by sal, empno) as 누적합
from emp;
해결2) 범위 수정(range -> rows)
select empno, ename, deptno, sal,
sum(sal) over(order by sal
rows between unbounded preceding and current row) as 누적합
from emp;
결과는 동일하게 나오는 것을 알 수 있고, 4번과 5번쪽에 동시 연산이 되지 않고 따로 누적합을 구해냄을 알 수 있다.
예제) 각 직원의 이름, 부서번호, 급여와 함께 부서별 급여의 누적합(급여 작은순서대로)
select ename, deptno, sal,
sum(sal) over(partition by deptno
order by sal) as 누적합1,
sum(sal) over(partition by deptno
order by sal, empno) as 누적합2,
sum(sal) over(partition by deptno
order by sal
rows between unbounded preceding and current row) as 누적합3
from emp;
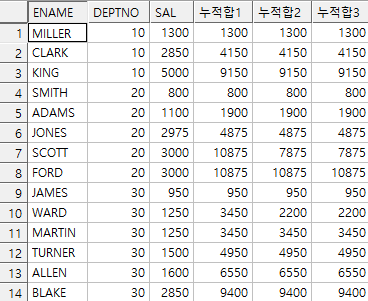
이처럼 누적합의 차이에 대해 문제와 예시로 살펴볼 수 있다.
[ 연습문제 ]
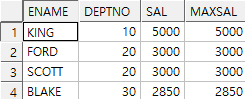
1. emp에서 각 부서별 최대 급여자 찾기(이름, 부서번호, 급여)
sol1) 인라인뷰 이용한 방식
select e.ename, e.deptno, e.sal
from emp e, (select deptno, max(sal) as maxsal
from emp
group by deptno) i
where e.deptno = i.deptno
and e.sal = i.maxsal;
sol2) 윈도우 함수 이용 방식
select *
from (select e.ename, e.deptno, e.sal,
max(sal) over(partition by deptno) as maxsal
from emp e)
where sal = maxsal;
결과)
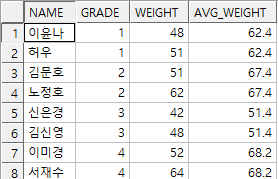
2. student에서 각 학년별 평균몸무게보다 작게 나가는 체중의 학생 출력(이름, 학년, 체중)
sol1) 서브쿼리 이용
select s.name, s.grade, s.weight
from student s
where s.weight < (select avg(weight)
from student
where grade = s.grade);
sol2) 윈도우 함수 이용
select *
from (select s.name, s.grade, s.WEIGHT,
avg(s.weight) over(partition by s.grade) as avg_weight
from student s)
where weight < avg_weight;
결과)
[ 순위 관련 윈도우함수 ]
1. rank
** rank() over([partition by ...]
order by
[range|rows ...])
2. dense_rank
3. row_number
** 차이점
- rank, dense_rank 는 동순위 인정(값이 같은 경우 동일한 순위 리턴), row_number는 값이 같아도 서로 다른 숫자 리턴
- 동순위가 발생한 경우 다음 순위 부여방식이 rank는 동순위 숫자만큼 반영, dense_rank 바로 순위가 이어지도록
예제) 각 직원의 급여 큰 순서대로 순위 (전체 기준)
select ename, sal, deptno,
rank() over(order by sal desc) as 순위1,
dense_rank() over(order by sal desc) as 순위2,
row_number() over(order by sal desc) as 순위3
from emp;
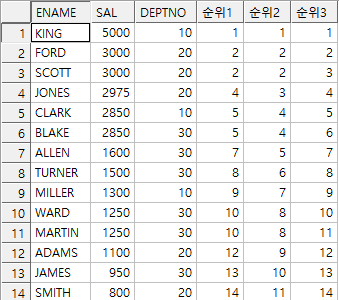
다음 예시의 대한 해답으로 rank, dense_rank, row_number의 차이를 알 수 있다.
이 중에 동순위를 인정해 주는 방식은 rank,dense_rank 두개이고 차이점을 구별하는것이 중요하다.
[ 연습문제 ]
1. 각 학년별로 성적이 높은순 3명 출력
create table STUDENT_EXAM01
as
select s.studno, s.name, s.grade, e.total
from student s, exam_01 e
where s.STUDNO = e.STUDNO;
sol)
select *
from (select s.*,
rank() over(partition by grade order by total desc) 순위1,
dense_rank() over(partition by grade order by total desc) 순위2,
row_number() over(partition by grade order by total desc) 순위3
from student_exam01 s)
where 순위3 <= 3;
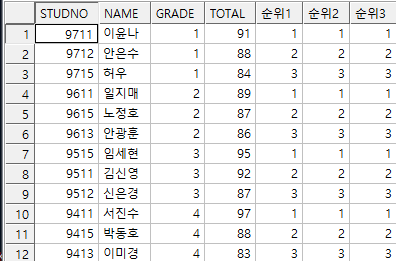
2. 전체 성적이 높은순 3명 출력
sol1)
select *
from (select s.*,
row_number() over(order by total desc) 순위
from student_exam01 s)
where 순위 <= 3;
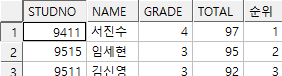
sol2)
select rownum,
s.*
from student_exam01 s
where rownum <= 3; -- 잘못된 쿼리(행 입력순서대로 rownum 부여)
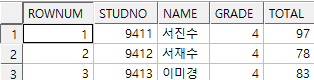
select rownum,
s.*
from student_exam01 s
where rownum <= 3
order by total desc; -- 잘못된 쿼리(order by 전에 where절이 수행되므로 성적순서대로의 rownum 부여 불가)
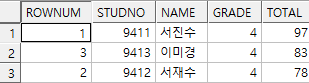
select rownum, i.*
from (select *
from student_exam01 s
order by total desc) i
where rownum <= 3; -- 올바른 쿼리!!!!!!
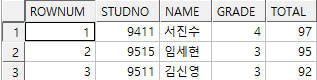
3. 전체 성적순으로 4~6등 출력(동순위 인정X)
sol1)
select *
from (select s.*,
row_number() over(order by total desc, name) 순위
from student_exam01 s)
where 순위 between 4 and 6;
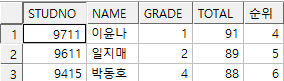
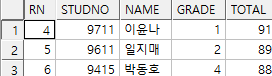
sol2)
select *
from (select rownum as rn, i.*
from (select *
from student_exam01 s
order by total desc, name) i)
where rn between 4 and 6;
[ 이전/이후 행 윈도우함수 ]
1. lag : 이전값 가져오기
ex) 이전달 실적 비교
** 문법
lag(대상,
[n], -- 가져올 값의 위치(default : 1)
[대체값]) -- 가져올 값이 없을 경우 리턴값(default : null)
over([partition by ...]
order by ...);
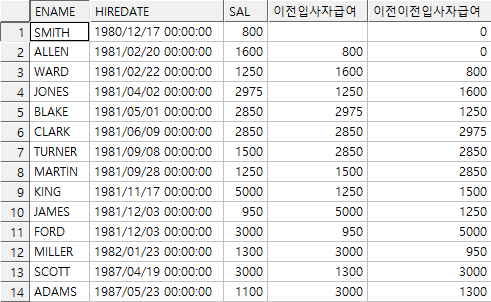
예)
select ename, hiredate, sal,
lag(sal) over(order by hiredate) as 이전입사자급여,
lag(sal,2,0) over(order by hiredate) as 이전이전입사자급여
from emp;
예제) 바로 직전에 입사한 직원의 급여보다 낮은 급여를 받는 직원 출력
select *
from (select ename, hiredate, sal,
lag(sal) over(order by hiredate) as 이전입사자급여
from emp)
where sal < 이전입사자급여;
2. lead : 이후값 가져오기
-** 문법
lead(대상,
[n], -- 가져올 값의 위치(default : 1)
[대체값]) -- 가져올 값이 없을 경우 리턴값(default : null)
over([partition by...]
order by ...);
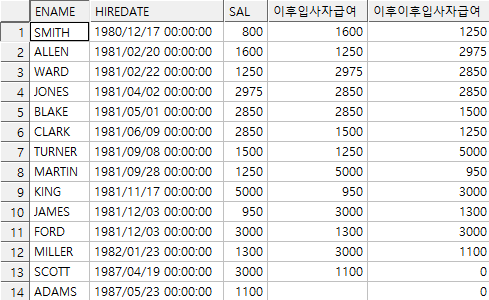
예)
select ename, hiredate, sal,
lead(sal) over(order by hiredate) 이후입사자급여,
lead(sal,2,0) over(order by hiredate) 이후이후입사자급여
from emp;
[ 연습문제 ]
1) 일자별 이용비율 총 합 출력 후 테이블 생성(movie_t1)
create table movie_t1
as
select 년||lpad(월,2,'0')||lpad(일,2,'0') as 날짜, sum(이용비율) as 이용비율
from movie
group by 년||lpad(월,2,'0')||lpad(일,2,'0')
order by 1;
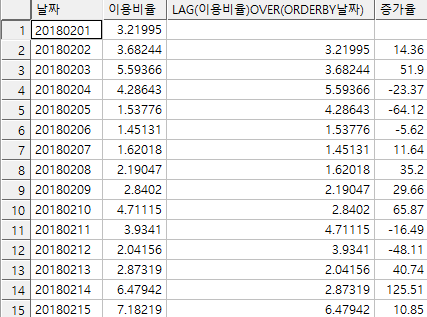
2) 이전일자대비 이용비율 증가율
select 날짜,
round((이용비율-lag(이용비율) over(order by 날짜)) / lag(이용비율) over(order by 날짜)*100,2) as 증가율
from movie_t1;
[ top n query ]
- 상위 n개 추출
- 정렬 필수
- 페이징 처리
1. fetch
- 대부분의 dbms 제공
- oracle에서 12c부터 제공
- 단일 쿼리로도 상위 n개 추출
2. rownum
- 출력되는 순서에 맞게 1,2,3의 항상 1씩 증가하는 번호 부여
- 일반적으로 입력순서에 따라 rownum부여, 사용자 정의 순서대로 rownum 부여 시 서브쿼리 사용 필요
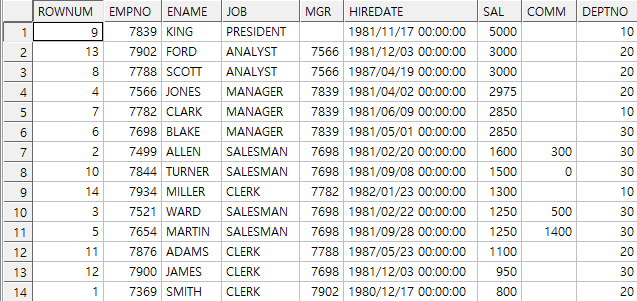
예제) rownum을 사용하여 급여 순위
select rownum, e.*
from emp e
order by sal desc; -- 원하는 순서대로 출력되지 X -> rownum 먼저 부여 후 정렬했기 때문
select rownum, i.*
from (select *
from emp
order by sal desc) i -- 원하는 순서대로 출력됨
where rownum <= 3;

3. rank over / dense_rank over/ row_number over
cf) top(n)
- SQL-Server 문법
- 단일 쿼리로도 상위 n개 추출
[ 처음/마지막 값 윈도우 함수 ]
1. first_value : 시작값
** 문법
first_value(대상) over([partition by ...]
[order ...]
[range|rows ....]);
2. last_value : 마지막값
예제) 시작값과 끝값 출력
select e.*,
first_value(sal) over(order by sal) as "FIRST_VALUE",
last_value(sal) over(order by sal) as "LAST_VALUE"
from emp e
where job = 'CLERK'
order by sal;

=> 각각 시작값과 마지막값을 리턴하지만 지정된 범위는 처음부터 현재행까지이므로
first_value는 최솟값을 출력, last_value는 각 행의 값을 출력하게 된다.
예제) 최소, 최대 출력
select e.*,
first_value(sal) over(order by sal) as 최소,
first_value(sal) over(order by sal desc) as 최대
from emp e
where job = 'CLERK'
order by sal;

select e.*,
last_value(sal) over(order by sal) as 자기자신,
last_value(sal) over(order by sal
range between unbounded preceding and unbounded following) as 최대,
last_value(sal) over(order by sal desc
range between unbounded preceding and unbounded following) as 최소
from emp e
where job = 'CLERK'
order by sal;

'SQL' 카테고리의 다른 글
| 30. 계층형 질의, 그룹 함수 (0) | 2024.11.06 |
|---|---|
| 29. 윈도우함수(2) (0) | 2024.11.06 |
| 27. 정규식표현(2) (0) | 2024.11.05 |
| 26. 정규식표현(1) (1) | 2024.11.04 |
| 25. 기타 오브젝트(3) (0) | 2024.11.01 |


